
Apache Hadoop 是一个基于 Java 编写的免费开源软件框架,通过 MapReduce 技术用于实现大数据的分布式存储与处理。它通过将海量数据集分割为大型数据块,并将其分布在集群中的多台计算机上,从而处理超大规模的数据集。
Hadoop 模块的设计理念并非依赖标准操作系统集群,而是通过在应用层检测和管理故障,从而在软件层面为用户提供高可用性服务。
基础 Hadoop 框架由以下模块构成:
Hadoop Common:包含支持其他 Hadoop 模块的通用库和实用工具集。
Hadoop 分布式文件系统(HDFS):基于 Java 的分布式文件系统,可在标准硬件上存储数据,为应用程序提供超高吞吐量。
Hadoop YARN:管理计算集群上的资源,并调度用户应用程序。
Hadoop MapReduce:基于 MapReduce 编程模型的大规模数据处理框架。
本文将介绍如何在 Rocky Linux 8 上安装 Apache Hadoop,该教程同样适用于 CentOS 8、OpenEuler 等其他基于 RHEL 8 的发行版。
准备工作
1. 安装 OpenJDK 8
对于绝大多数 Hadoop 部署(包括 2.x 晚期和 3.x 版本),OpenJDK 8 是目前经过最广泛验证、兼容性最佳且最稳定的选择。相较而言,Oracle JDK 因其许可模式已不再是社区标准,而 OpenJDK 11 及更高版本则普遍面临 Hadoop 自身及其生态系统(如 Spark、Hive)的兼容性问题。因此本教程将使用 OpenJDK 8 进行演示:
$ sudo dnf install java-1.8.0-openjdk wget -y检查 Java 版本:
$ java -version输出内容如下:
openjdk version "1.8.0_462"
OpenJDK Runtime Environment (build 1.8.0_462-b08)
OpenJDK 64-Bit Server VM (build 25.462-b08, mixed mode)2. 创建 Hadoop 用户
出于安全考虑,推荐使用普通用户(非 root 用户)来运行 Apache Hadoop。因此,我们首先创建一个名为 hadoop 的专用用户,并为其设置密码。以 root 用户权限执行以下命令:
$ sudo useradd -m -d /home/hadoop -s /bin/bash hadoop
$ passwd hadoop # 为 Hadoop 用户设置密码3. 配置 SSH 免密登录
Hadoop 集群的守护进程(Daemons)之间需要通过 SSH 进行通信。为了实现自动化和无缝操作,我们需要配置“无密码 SSH”登录功能。
首先,切换到新创建的 hadoop 用户:
$ su - hadoop接下来,作为 hadoop 用户执行以下步骤:
# 1. 生成 SSH 密钥对(公钥和私钥)
# 在提示时,直接一直按回车键接受默认路径和空密码 (passphrase)
$ ssh-keygen
# 2. 将公钥追加到本机的“授权密钥”列表中
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# 3. 设置正确的权限,确保 authorized_keys 文件的安全
# (只有所有者可读写)
$ chmod 600 ~/.ssh/authorized_keys3. 验证连接
完成上述配置后,验证 hadoop 用户免密登录是否生效:
$ ssh 127.0.0.1如果第一次通过 SSH 连接到该主机,系统会提示确认主机的真实性。输入 yes,将该主机的公钥指纹添加到已知主机列表(~/.ssh/known_hosts)中。
此时会看到类似以下的输出:
$ ssh 127.0.0.1
The authenticity of host 'localhost (::1)' can't be established.
ECDSA key fingerprint is SHA256:jdKvVL4YEH0GFVKc0lPtsWSrAGckeviAsTtQWPbulaM.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added '127.0.0.1' (ECDSA) to the list of known hosts.
Activate the web console with: systemctl enable --now cockpit.socket
Last login: Tue Oct 21 20:05:30 2025当您看到最后的登录信息并返回命令提示符,且全程未被要求输入密码时,即表示 SSH 免密登录已成功配置。
安装 Hadoop
Hadoop 集群类型
Hadoop 通常根据其部署和运行方式,分为三种模式(或类型):
1. 本地(独立)模式 (Local/Standalone Mode)
这是 Hadoop 的默认运行模式,也是最简单的模式。
特点:它在单个 Java 虚拟机 (JVM) 进程中运行所有组件。它不使用 Hadoop 的分布式文件系统 (HDFS),而是使用本机的本地文件系统进行读写。
用途:这种模式主要用于开发和调试 MapReduce 程序的业务逻辑,因为它启动速度快,不需要复杂的配置,便于开发者快速验证代码。
2. 伪分布式模式 (Pseudo-Distributed Mode)
这是一种在单台机器上模拟真实集群环境的模式。
特点:Hadoop 的所有守护进程(如 NameNode, DataNode, ResourceManager, NodeManager)都在同一台机器上运行,但它们是作为独立的 Java 进程启动的。这种模式会真正使用 HDFS。
用途:用于测试和验证 Hadoop 的完整功能,包括 HDFS 的使用、MapReduce 任务的执行流程以及配置文件的正确性。配置的“无密码 SSH”就是为这种模式(以及完全分布式模式)做准备。
3. 完全分布式模式 (Fully-Distributed Mode)
这是 Hadoop 在生产环境中的标准部署模式。
特点:Hadoop 运行在一个由多台物理机器组成的真实集群上。集群中包含专用的主节点(Master Nodes,运行 NameNode 和 ResourceManager)和多个从节点(Slave Nodes,运行 DataNode 和 NodeManager)。数据被真正地“分布式”存储在不同的从节点上,计算任务也会被分发到这些节点上并行处理。
用途:用于处理大规模数据集的实际生产环境,它提供了高可用性、容错能力和强大的横向扩展能力。
本教程将以伪分布式模式(Pseudo-Distributed Mode)配置 Hadoop。
1. 下载 Hadoop
访问 Apache Hadoop 的官方网站以下载最新版本的 Apache Hadoop(务必根据文档中的说明选择适合生产环境的版本);或者,您也可以在终端中使用以下命令来下载 Hadoop v3.4.2:
$ wget https://dlcdn.apache.org/hadoop/common/hadoop-3.4.2/hadoop-3.4.2.tar.gz
$ tar -xzvf hadoop-3.4.2.tar.gz
$ mv hadoop-3.4.2 hadoop国内用户也可以使用阿里云开源镜像站进行下载,速度更快:
$ wget https://mirrors.aliyun.com/apache/hadoop/common/hadoop-3.4.2/hadoop-3.4.2.tar.gz2. 设置环境变量
在 ~/.bashrc 文件中设置环境变量。根据实际需求,修改文件中的 JAVA_HOME 和 HADOOP_HOME 变量值:
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.462.b08-2.el8.x86_64/
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin使用下面命令将环境变量应用到当前的终端会话中:
$ source ~/.bashrc3. 配置 Hadoop
编辑 Hadoop 环境配置文件:
$ vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh将 JAVA_HOME 环境变量添加到 hadoop-env.sh:
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.462.b08-2.el8.x86_64/进入 Hadoop 配置文件目录,准备以伪分布式模式进行配置:
$ cd $HADOOP_HOME/etc/hadoop编辑 core-site.xml,填写 Hadoop 服务器主机名等属性:
$ vim core-site.xml<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://HXCN-Rokey8-Hpv:9000</value>
</property>
</configuration>其中,主机名 HXCN-Rokey8-Hpv 是系统上的主机名,可以输入下面命令查看系统主机名:
$ hostname在 Hadoop 用户目录 /home/hadoop 下,创建 namenode 和 datanode 目录:
$ mkdir -p ~/hadoopdata/hdfs/{namenode,datanode}编辑 hdfs-site.xml 文件,配置 NameNode 和 DataNode 的实际目录位置等信息:
$ vim hdfs-site.xml<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>编辑 mapred-site.xml 文件:
$ vim mapred-site.xml<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop/hadoop</value>
</property>
</configuration>编辑 yarn-site.xml 文件:
$ vim yarn-site.xml<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>使用以下命令来格式化 NameNode:
$ hdfs namenode -format输出内容如下:
$ hdfs namenode -format
WARNING: /home/hadoop/hadoop/logs does not exist. Creating.
2025-11-04 20:17:33,884 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = HXCN-Rokey8-Hpv/172.23.36.186
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.4.2
......
2025-11-04 20:17:34,415 INFO namenode.FSImage: Allocated new BlockPoolId: BP-304305349-172.23.36.186-1762258654410 # 系统为您的 HDFS 集群生成了一个唯一的ID
2025-11-04 20:17:34,439 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted. # hdfs-site.xml 中配置的 dfs.namenode.name.dir 目录已经被成功格式化为 HDFS 的元数据存储目录
......
2025-11-04 20:17:34,510 INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 401 bytes saved in 0 seconds . # 初始的元数据镜像文件 `fsimage` 已经被成功创建并保存
......
2025-11-04 20:17:34,533 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at HXCN-Rokey8-Hpv/172.23.36.186
************************************************************/ # 正常的关闭信息format 命令是一个一次性操作,执行成功后会自动关闭进程。这个日志表明了进程是正常退出的。
在 Rokey Linux 8 中安装,可能出现下面报错:
2025-11-04 20:17:34,033 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable这是一个非常常见的警告,可以暂时忽略。它意味着 Hadoop 没有找到针对您操作系统的优化过的本地库,所以会使用纯 Java 的实现来替代。在生产环境中为了追求极致性能会去解决它,但在学习和单节点测试环境中,这对功能没有任何影响。
4. 配置防火墙
运行以下命令允许 Apache Hadoop 通过防火墙建立连接。请以 root 用户或者带有 sudo 权限的账户执行命令:
$ firewall-cmd --permanent --add-port=9870/tcp
$ firewall-cmd --permanent --add-port=8088/tcp
$ firewall-cmd --reload启动 Hadoop 和 Yarn
启动脚本
由于前面的步骤设置了 ~/.bashrc 环境变量,直接运行下面命令启动 NameNode 和 DataNode 两个守护进程:
$ start-dfs.shstart-dfs.sh 位于 $HADOOP_HOME/sbin 目录下,专门用来存放管理和启动 / 停止 Hadoop 服务的脚本。这意味着可以在任何目录下直接运行这个命令,不需要切换到 sbin 目录。
执行启动脚本后,输出内容如下:
$ start-dfs.sh
Starting namenodes on [HXCN-Rokey8-Hpv]
HXCN-Rokey8-Hpv: Warning: Permanently added 'hxcn-rokey8-hpv,172.23.36.186' (ECDSA) to the list of known hosts.
Starting datanodes
Starting secondary namenodes [HXCN-Rokey8-Hpv]
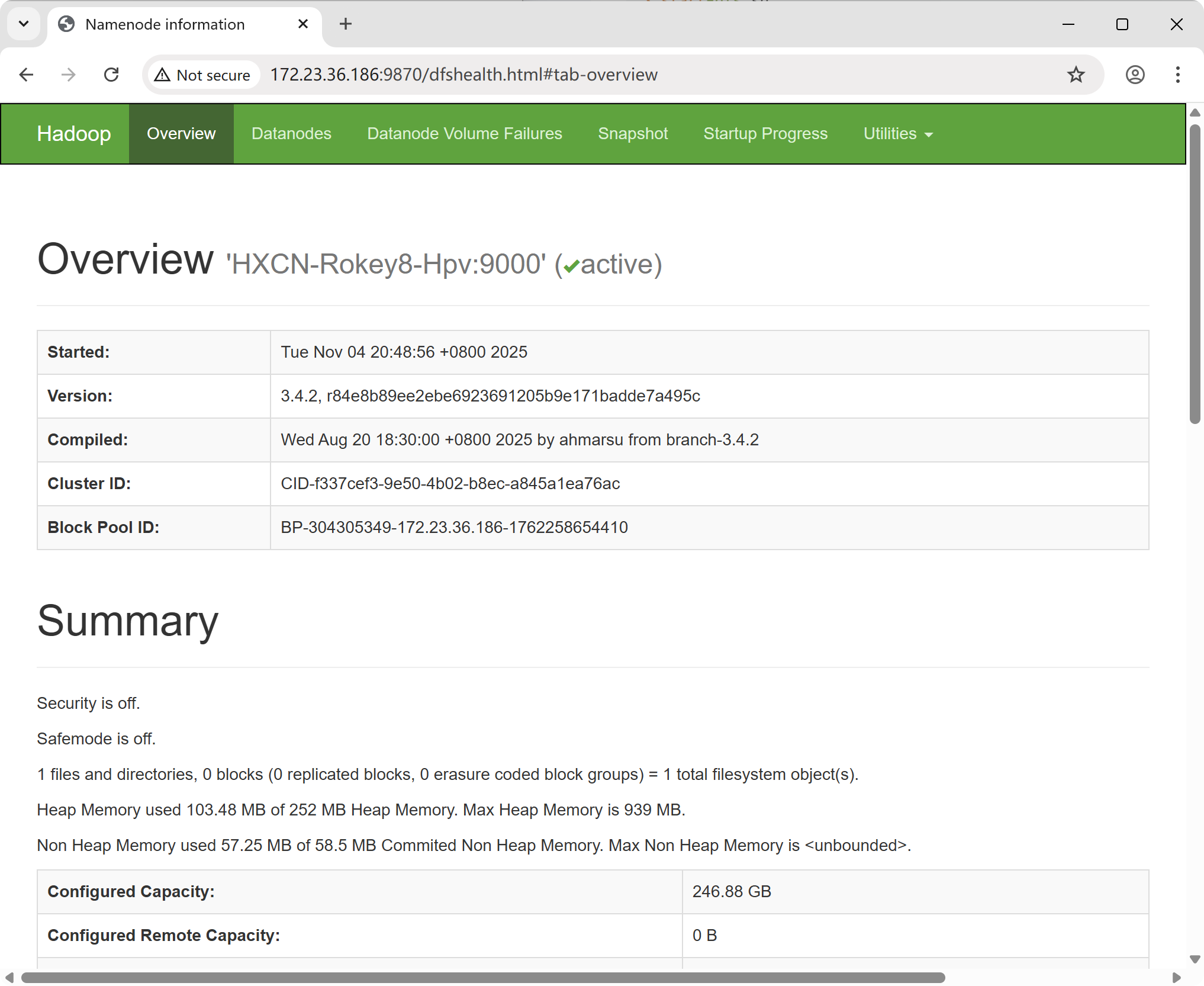
2025-11-04 20:49:03,256 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable在浏览器中输入下面地址,访问 Namenode,就可以看到 Hadoop NameNode 的信息:
http://<hadoop_ip>:9870/将 <hadoop_ip> 替换为执行启动脚本后输出日志中的 IP 地址。
使用下面命令启动 ResourceManager 和 NodeManager:
$ start-yarn.sh执行启动脚本后,输出内容如下:
Starting resourcemanager
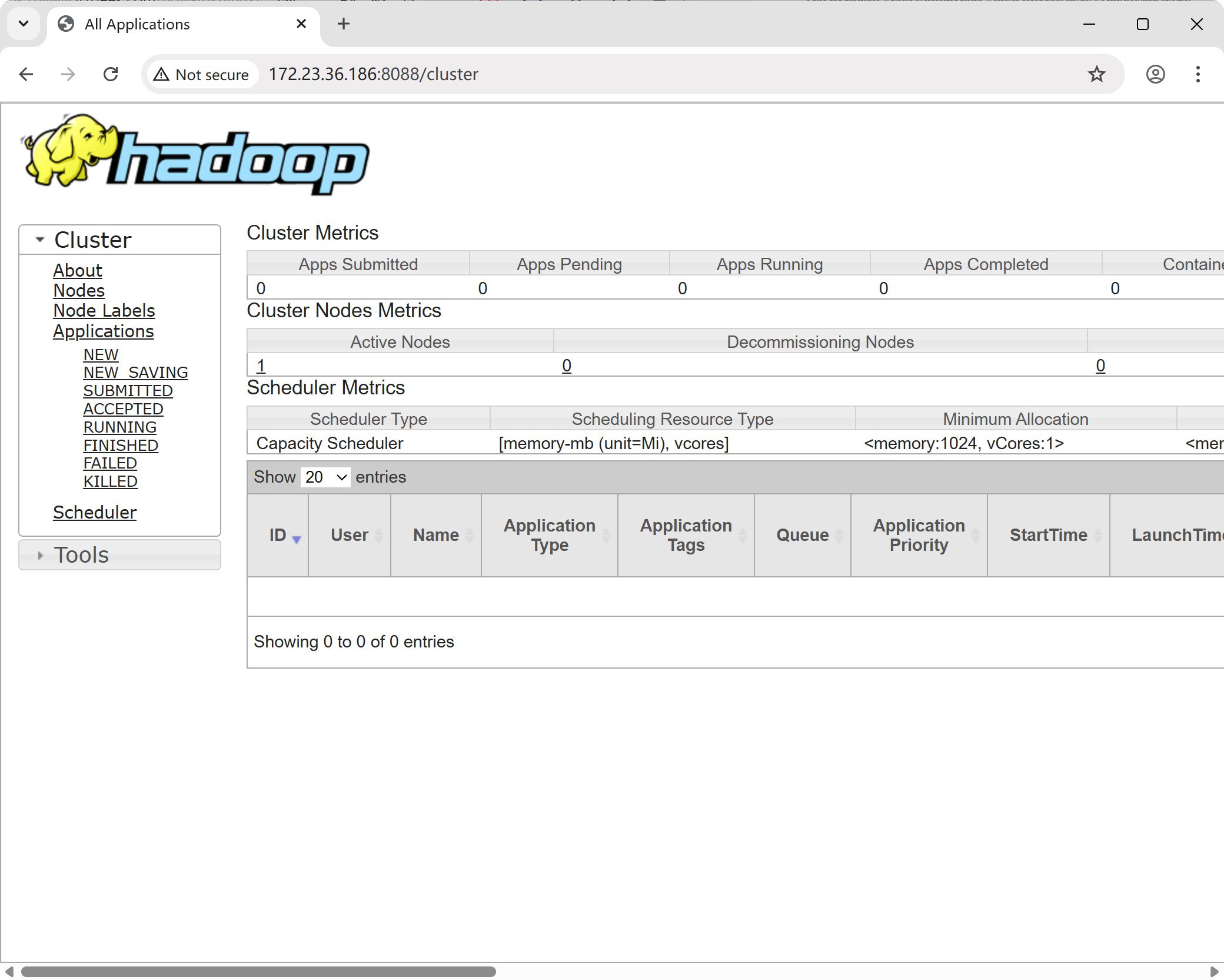
Starting nodemanagers在浏览器中输入下面地址,访问 Namenode,就可以看到 ResourceManager 组件:
http://<hadoop_ip>:8088/将 <hadoop_ip> 替换为执行启动脚本后输出日志中的 IP 地址。
输入下面命令,检查 NameNode, DataNode 和 SecondaryNameNode 进程是否可以正常运行:
$ jps
5474 SecondaryNameNode
5939 ResourceManager
5254 DataNode
35798 Jps
6107 NodeManager
5068 NameNode如果首次运行 jps 命令,需要切换到 root 用户,输入 jps 命令安装软件包方可执行。
start-dfs.sh
这个脚本负责启动 HDFS (Hadoop Distributed File System) 的所有服务,具体包括:
NameNode:HDFS 的主节点,负责管理文件系统的元数据(比如文件名叫什么、在哪里存储等)。
DataNode(s):HDFS 的从节点,负责实际存储文件数据块。
SecondaryNameNode:辅助 NameNode 进行元数据检查点操作,防止元数据丢失。
start-yarn.sh
这个脚本负责启动 YARN (Yet Another Resource Negotiator) 的所有服务,YARN 是 Hadoop 的资源管理和作业调度框架。具体包括:
ResourceManager:YARN 的主节点,负责整个集群的资源管理和分配。
NodeManager(s):YARN 的从节点,负责管理单个节点上的资源,并执行 ResourceManager 分配的任务。
start-all.sh
此外,也可以使用下面命令执行依次启动两个脚本:
$ start-all.sh但在 Hadoop 2.x 版本及之后,start-all.sh 和 stop-all.sh 脚本已经被官方标记为“不推荐”(deprecated)。虽然它们为了方便仍然存在,但官方推荐的做法是分开启动 HDFS 和 YARN,这样可以更清楚地控制和了解集群的状态。
测试 Apache Hadoop
1. 文件上传
在 HDFS 中创建用户目录:
$ hdfs dfs -mkdir -p /user/hadoop创建 input 目录,用于输入数据:
$ hdfs dfs -mkdir input将所需的 xmi 配置文件复制到 input 中:
$ hdfs dfs -put $HADOOP_HOME/etc/hadoop/*.xml input可以通过运行以下命令来查看上传的文件:
$ hdfs dfs -ls input如果之前运行过 hadoop,则需要删除 output 目录:
$ hdfs dfs -rmdir output或者,可以使用浏览器访问 NameNode,选择 “Utilities”,然后点击 “Browse the file system in NameNode” 来浏览 NameNode 中的文件系统。
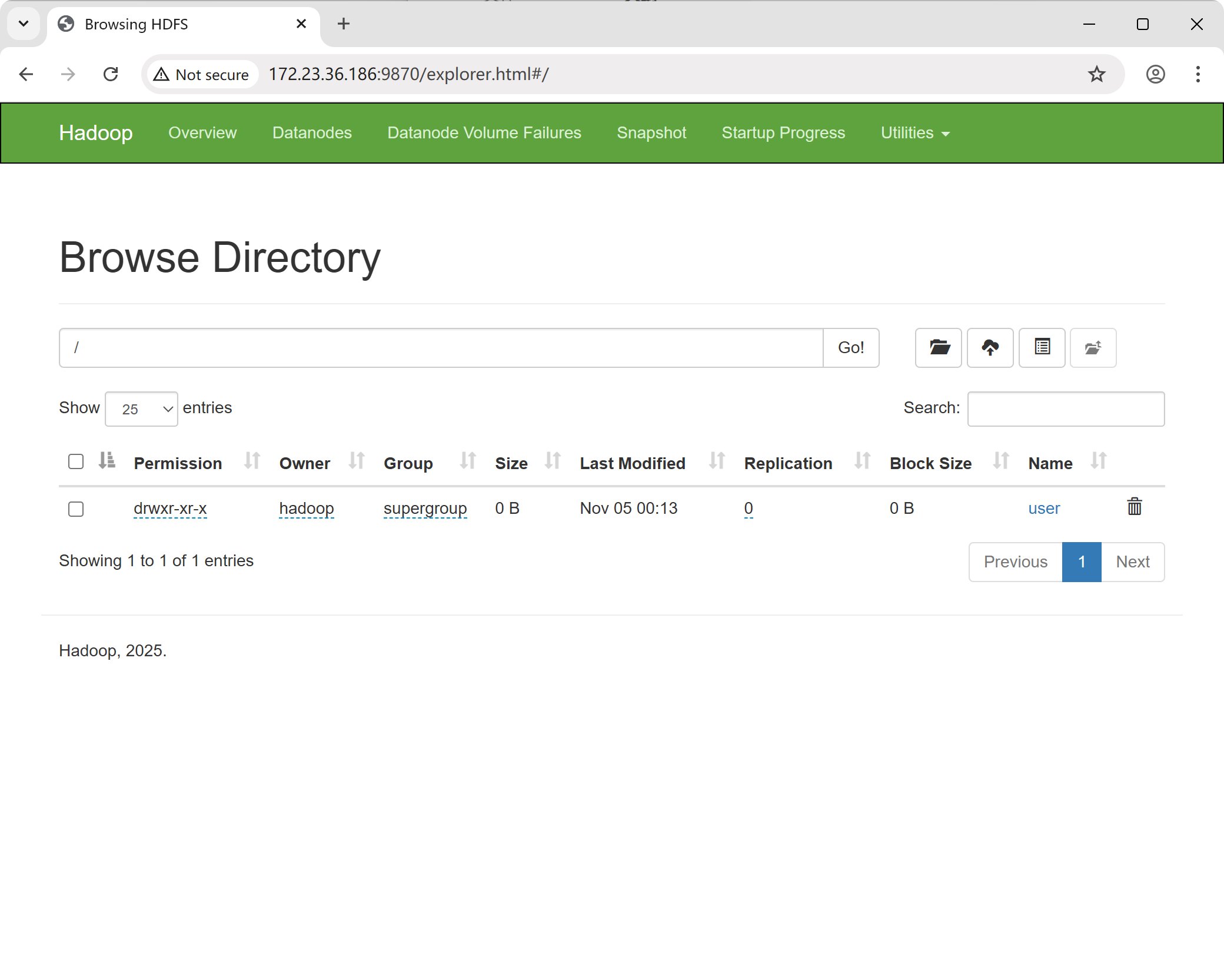
2. 调用实例
首先,进入 Hadoop 目录下:
$ cd ~/hadoop使用下面命令进行写入操作:
$ hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar wordcount /user/hadoop/input /user/hadoop/output运行结果如下:
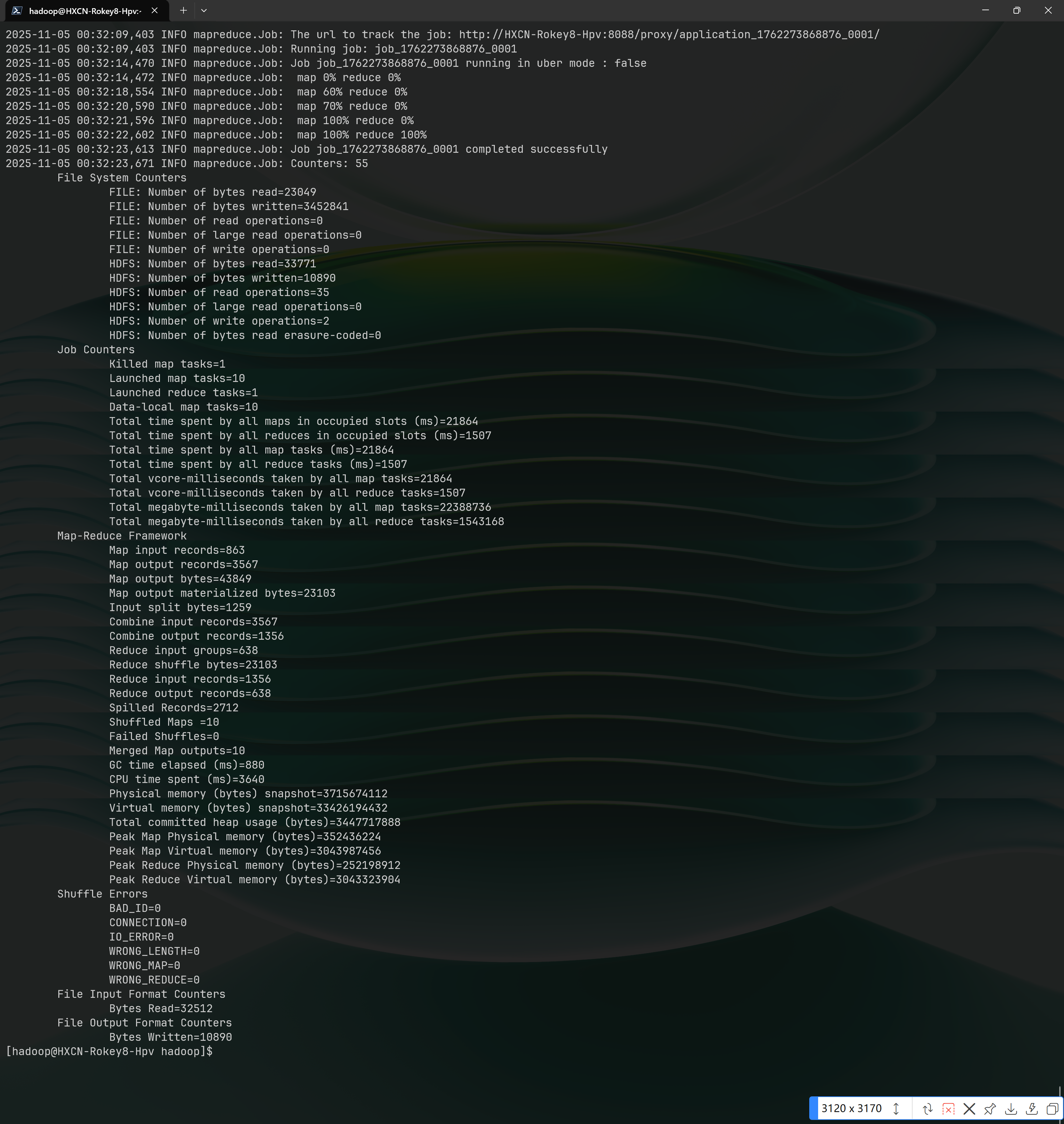
进入 Hadoop 下面的 bin 目录:
$ cd $HADOOP_HOME/bin查看运行结果:
hdfs dfs -ls ./output
hdfs dfs -cat output/*
结束了
以上是本人使用 Rokey Linux 8 配置 Hadoop 的全部过程。可以查阅 Apache Hadoop 官方文档 了解更多内容。