
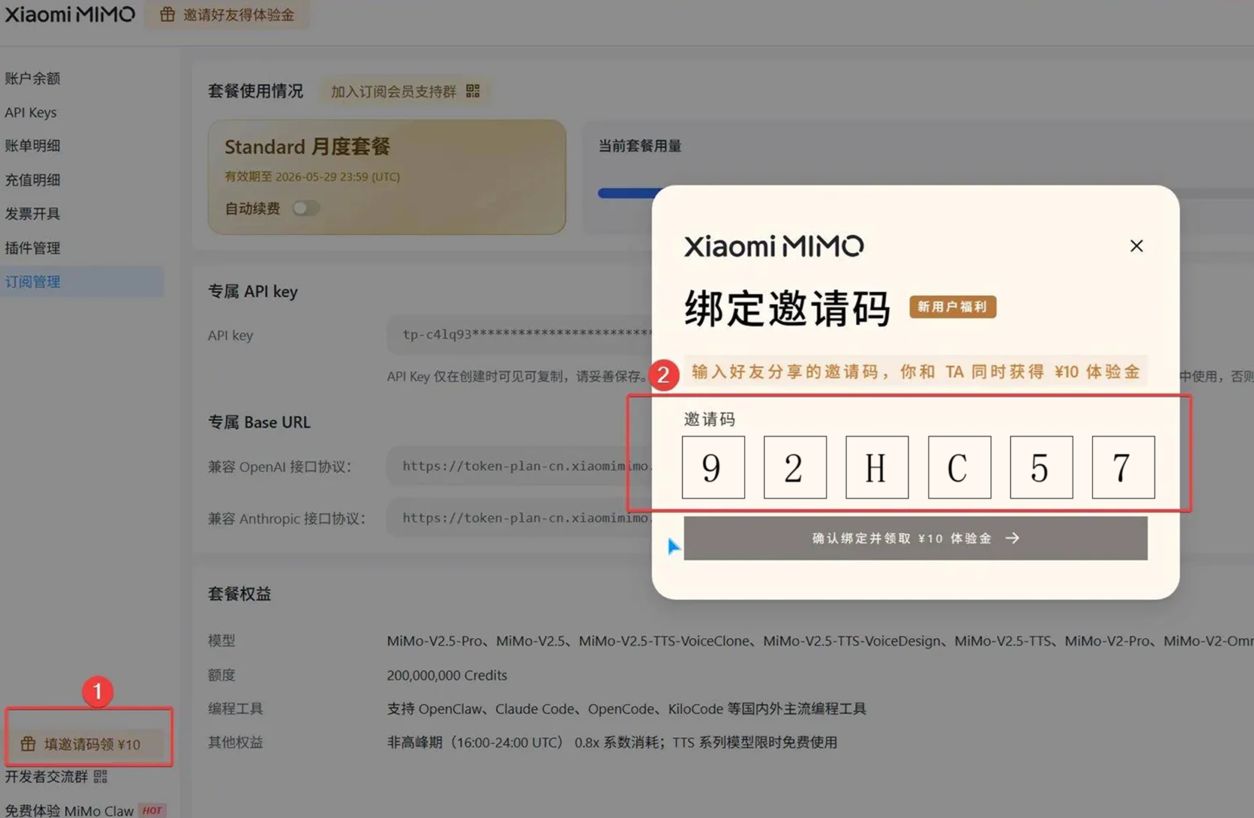
点击控制台,左下角的“填邀请码领¥10”,输入邀请码 92HC57,可获得 10 元体验金(领取后可以到账户余额查看):
一分钱可以白嫖额外的 20% 积分,具体操作步骤请看还有高手?!
官方公告转述(2026.05.27 更新)
据 Xiaomi MiMo 团队公告,团队近期持续优化推理性能,并将阶段性降本成果回馈给开发者,调整内容已于北京时间 2026.05.27 00:00 正式生效:
MiMo-V2.5 系列按量计费最高降幅 99%
Token Plan 加量不加价,Credits 用量提升至原来的 5–8 倍
有效期内已使用的 Credits 额度全量重置
同时,MiMo Orbit 百万亿 Token 创造者激励计划已圆满收官。该计划自 2026.04.28 上线以来反响热烈,截至 2026.05.26 16:08,100T Tokens 已全部发放完毕,活动提前结束。


雷总的恩情还不完✋😭🤚✋😭🤚
由于活动已于 2026 年 5 月 26 日提前结束,以下流程仅作为申请方法的存档供参考。
Xiaomi MiMo Orbit 百万亿 Token 创造者激励计划,是小米 MiMo 团队配合 MiMo-V2.5 系列发布搞的一波大额 Token 福利。从 2026 年 4 月 28 日开始到 5 月 28 日 00:00 截止,30 天里总共要发出去 100 万亿 Token。
主包一上午就拿到了 Pro 档计划,约 7 亿 Token,外加薅到了 2 亿 Token 的补偿额度。
审核看起来是 AI 跑的,所以材料怎么写很关键。这篇文章会把申请流程、踩坑点、接入 AI 工具的步骤以及模型速度实测都讲一遍。
申请流程
1. 注册 Mimo 开放平台
先访问 Xiaomi MiMo 开放平台(点击跳转),用国内手机号注册或者直接登录已有的小米账号都行。
注册完后再去 小米账号(点击跳转) 绑定邮箱,已有账号也要确认一下邮箱是否绑定。
这个邮箱后面会用来收审核通过的通知,一定要保证开放平台和小米账号上是同一个邮箱,否则无法领到权益。
2. 访问申请表单
访问 https://100t.xiaomimimo.com,点击「立即申请」,然后填写表单:

3. 「你的邮箱」
这里填的邮箱必须和 Xiaomi MiMo 开放平台(点击跳转)、小米账号(点击跳转) 上的一致。很多人就栽在这一步,邮箱对不上,权益就拿不到。
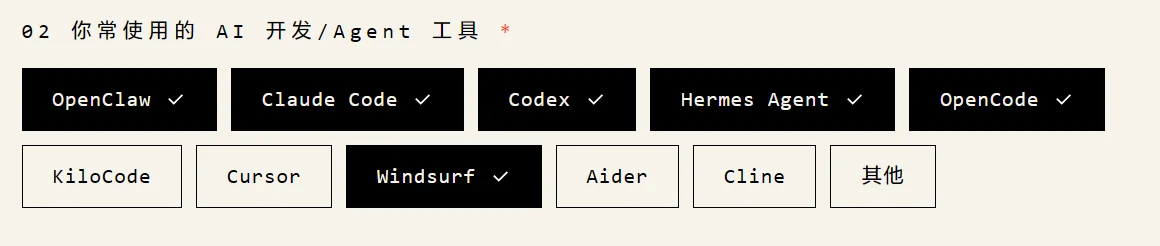
4. 「你常使用的 AI 开发/Agent 工具」
按真实情况勾,但别只选一个,也别全选,挑几个热门的就行。主包选的是 OpenClaw、Claude Code、Codex、Hermes Agent、OpenCode 和 Windsurf。
5. 「目前主要使用的底层模型系列」
同样按真实情况勾几个热门的就好。主包勾了 Claude、GPT、DeepSeek 和 MiniMax。

6. 「请描述你使用 Agent 或 AI 驱动构建的具体成果(认真填写可提升评估通过率/token plan 额度/赠金额度)」
请包含以下要素:1. 项目解决的核心痛点;2. 核心逻辑流(如是否包含长链推理、多 Agent 协作)。
这一项非常关键,直接决定能不能过审,以及拿到的是 Standard、Pro 还是 Max 档位。填写越详细、项目越具体,通过率和权益档位越高。主包翻了一堆经验帖加上自己实操,总结出几条值得注意的:
必须写真实项目和成果。光说 "在学 AI Agent"、"会用 AI Agent"、"想试试模型" 基本不会过。
详细描述 AI 使用场景,编程、Agent 开发、内容创作、多模态都行,越具体越好。
项目最好能蹭上 Agent、工作流(LangChain / Dify / n8n)、长文本推理、智能体协同、多模态、TTS/ASR 这些关键词。
把 Agent 的完整链路写出来,比如「需求理解→任务拆解→Agent 执行→结果评估→安全审核」这种闭环,再带上用了哪些底层模型、单轮 Token 消耗、日均请求量、效率提升数据。
如果做过大规模模拟实验、自动化运维或者高频 API 调用,务必写上。官方会量化你的 Token 消耗潜力,并且明显更愿意把额度给到真能把 Token "烧掉" 的人。
字数上限 1200,但不是越多越好。有人写满了拿 Pro,有人 300 字反而拿了 Max。把项目讲清楚就够了,别堆情怀和价值衬托。
主包写了一段提示词,丢给 Cursor / Claude Code / OpenCode 跑一下就能在项目目录里生成小作文,提示词附在文末。下面是最终的成品:
我基于 LangChain + FastAPI 构建了一套面向开发者的多智能体协同 AI 创作平台,使用 Qwen、Deepseek等底层模型和专业 Agent 协同工作,形成「需求理解→任务拆解→Agent 执行→结果评估→安全审核」的闭环流水线。
当前平台已服务 200+ 开发者,日均消耗 ¥183.60 ~ ¥347.25,Token 使用量 1,738k ~ 3,592k 不等,高峰期单日可达 ¥412.80。此外,平台通过 Redis 消息队列异步处理任务,高峰期单任务 Token 消耗可达数万。随着用户规模增长与多模态生成需求扩大,特申请更高 Token 额度以支撑更复杂的长链路推理与高质量生成。7. 使用证明与影响力证明(提交可提升评估通过率/token plan 额度/赠金额度)
可上传内容:
过去 30 天主流 AI 平台的账单截图;
终端运行日志或 Agent 工作流截图 / 录屏(优先提交上一个问题中描述的项目);
GitHub 项目链接或产品在线演示地址。
账单部分,主包是把 DeepSeek 和 Codex 的 4 月份的使用截图丢给 GPT,用 Image-2 模型生成了一张 DeepSeek 账单。
也可以用 SingleFile 浏览器插件 把账单页面整页保存下来再使用 AI 修改金额。
工作流截图就更简单了,有 LangGraph 或 Dify 直接截图就行,主包传的是 LangChain 的运行日志。
最后那栏是项目 Demo 或 GitHub 仓库。主包上传了在线 Demo 地址,仓库本身是私有的,就只截了一张提交记录的截图。
8. 提交和等待
填完点提交就等审核。主包是一上午就过了,也有人等了一两天才收到通知,耐心一点。如果三天还没收到评估通过的邮件,可以重新申请。

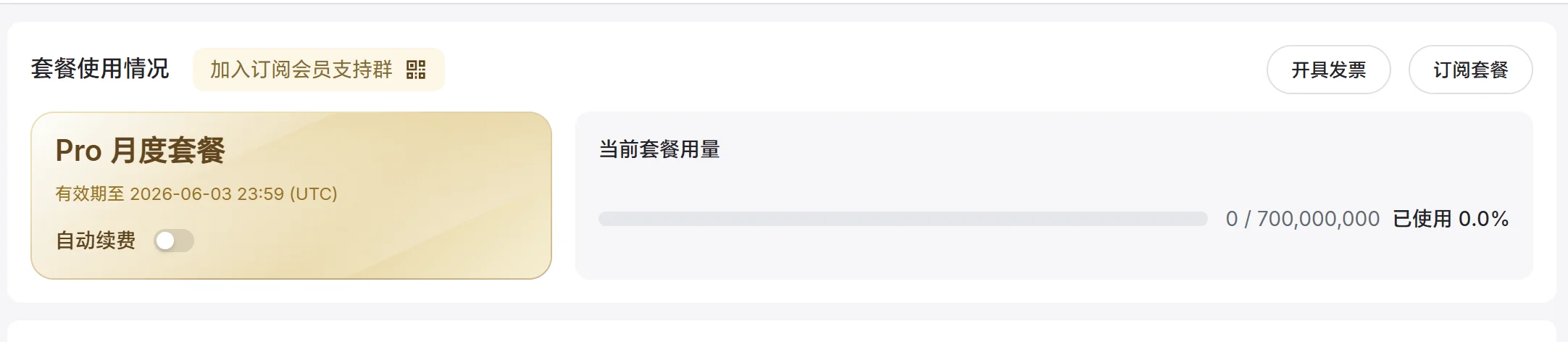
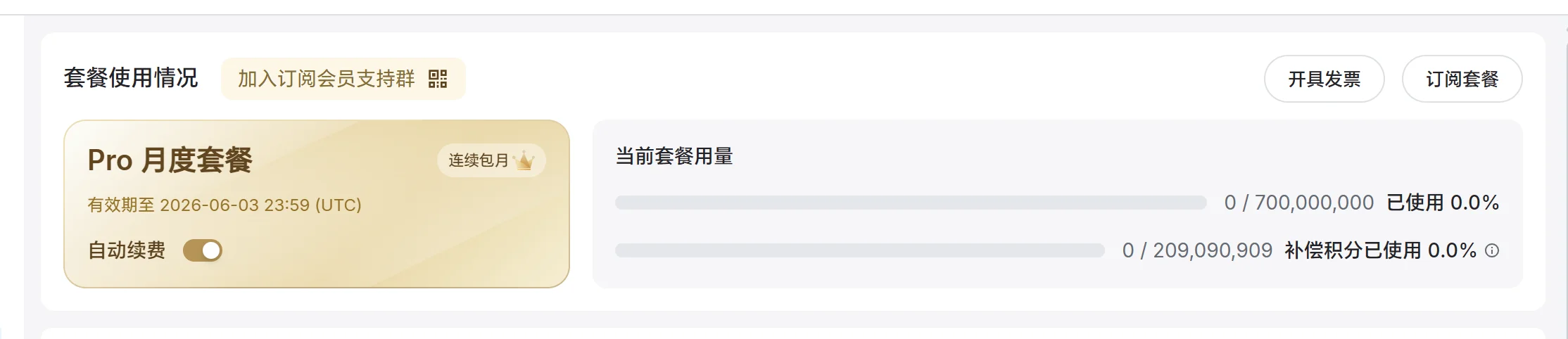
收到邮件后,访问 Xiaomi MiMo 开放平台订阅管理,即可查看赠送额度情况:
还有高手?!
翻经验帖时发现一个隐藏玩法:在订阅页面勾上自动续订会打 77 折,算下来实付是负数,但最低需要支付 1 分钱,付完之后能拿到 23% 的额外套餐转化用量。
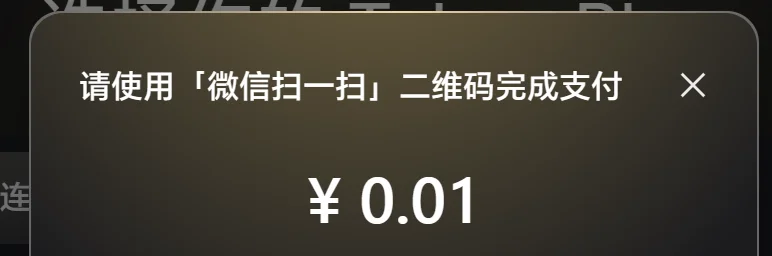
花了 1 分钱白嫖到 2 亿 Token 😭 雷总你真的真的我哭死。
不过有大佬连着续了两个月,补偿额度直接被取消了 🤣 所以只能薅一次。
开通之后一定记得关掉自动续费!!!
此外,点击控制台,左下角的“填邀请码领¥10”,输入邀请码 92HC57,可获得 10 元体验金(领取后可以到账户余额查看):

速度测试
主包用 LLM API Test 跑了两轮速度测试(时间是 2026 年 5 月 3 日),每轮三道题,提示词如下:
Explain the concept of "quantum entanglement" to a high school student, including its potential applications.
Discuss the primary ethical challenges posed by the rapid development of autonomous vehicles.
Write a short story about a sentient AI that discovers a hidden message within the internet's oldest data archives.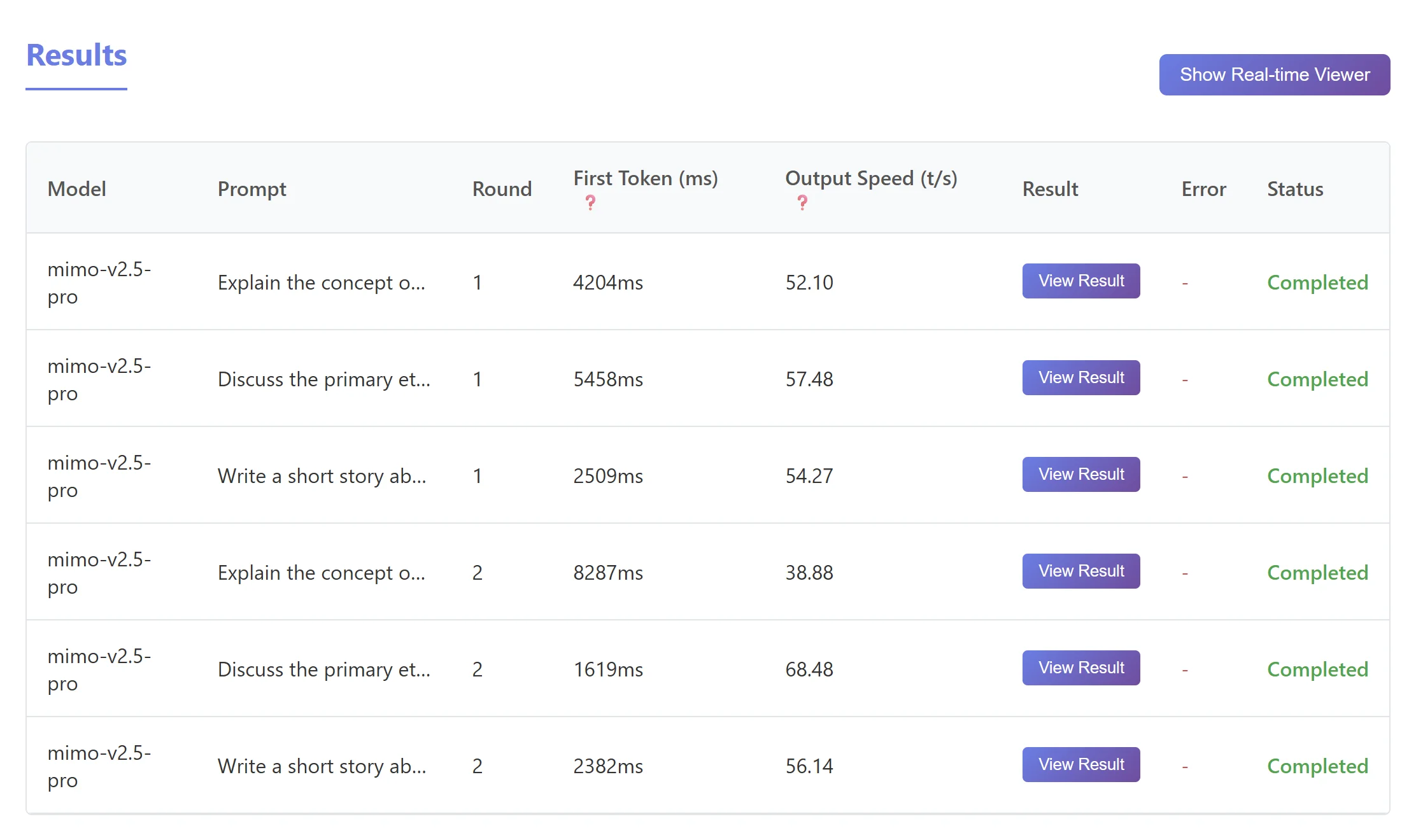
Mimo-V2.5 Pro 速度测试
Mimo-V2.5 速度测试
消耗情况如下:

而且补偿积分还是优先扣的,他真的我哭死。
再对比一下 DeepSeek V4 Pro、DeepSeek V4 Flash、MiniMax M2.7(Token Plan Starter):
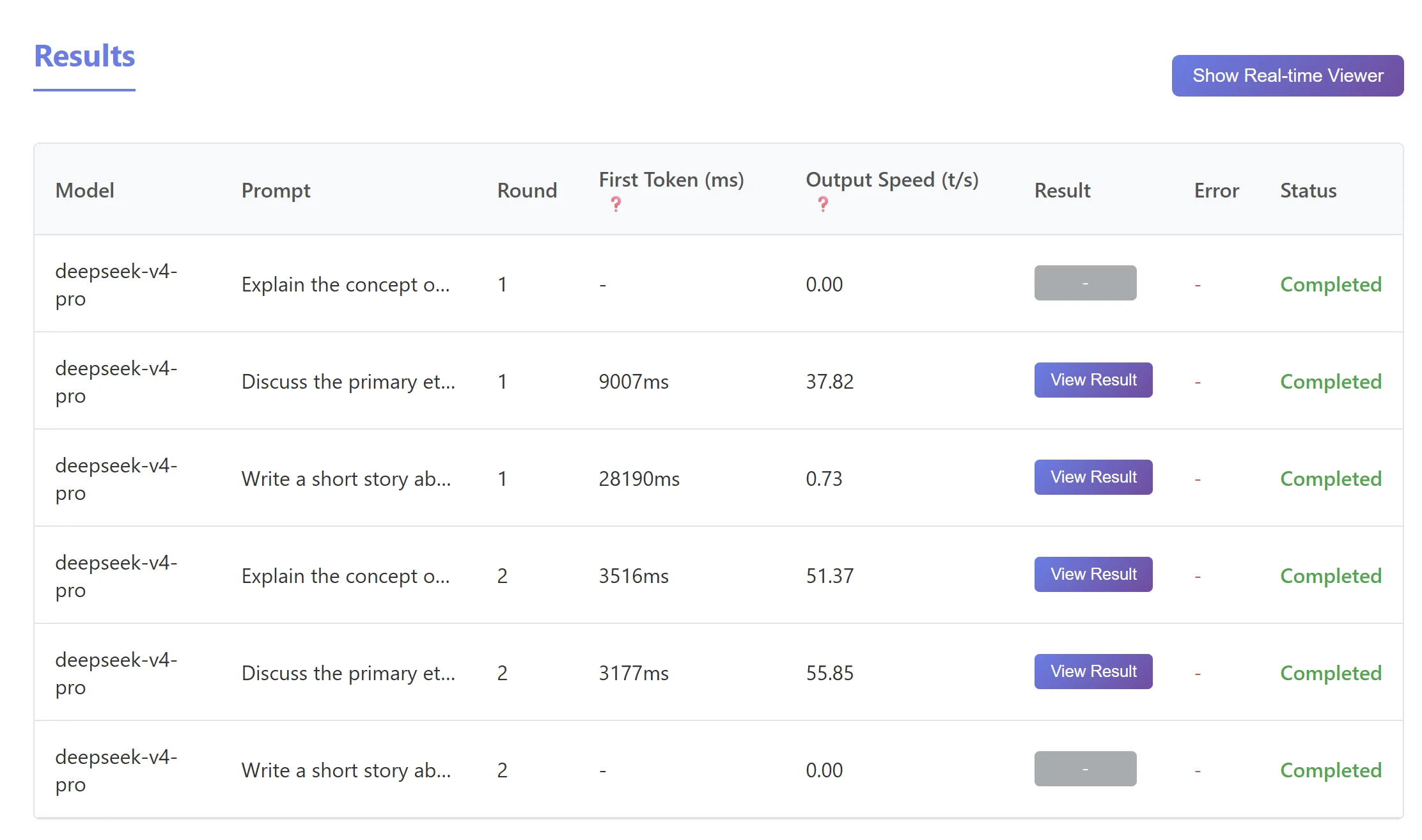
DeepSeek V4 Pro 速度测试
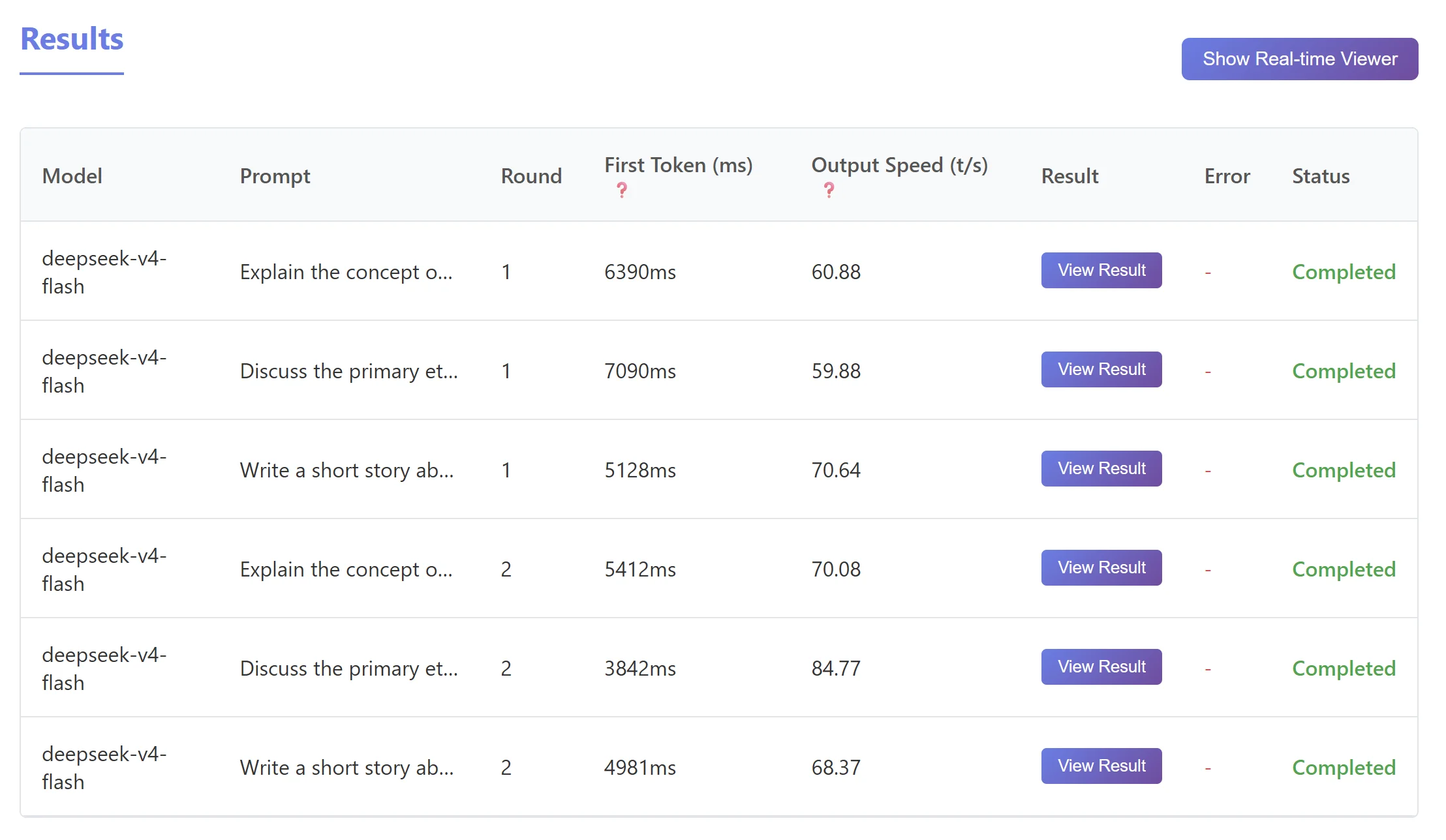
DeepSeek V4 Flash 速度测试
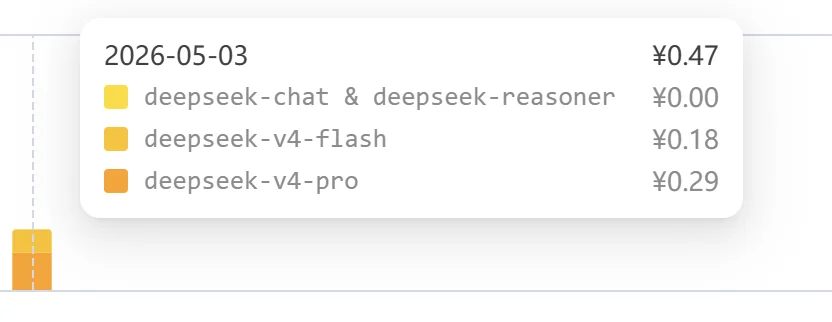
DeepSeek V4 测试费用消耗情况
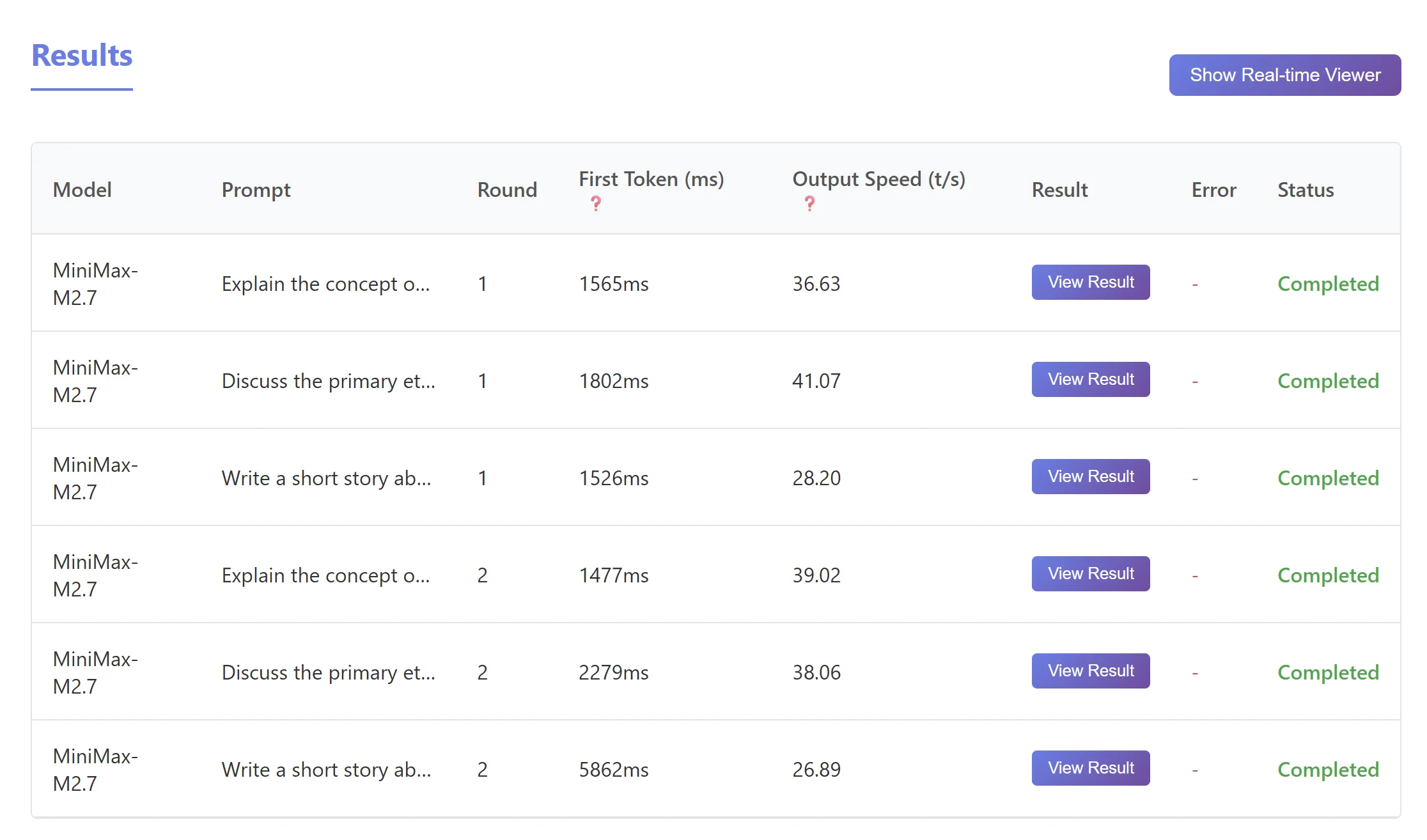
MiniMax M2.7(Token Plan Starter) 速度测试
汇总到一张表里看:
【附】小作文申请提示词
请你扮演一名资深 AI 项目申请材料撰写助手。
我将提供我的项目背景、使用过的 AI 工具/模型、工作流截图、成果链接和使用证明。你的任务不是编造愿景,而是基于我提供的真实材料,把内容整理成一份适合用于 Xiaomi MiMo Orbit 创作者激励计划的申请材料,重点突出我确实在用 AI 做项目,并且存在真实的 Token 消耗与 Agent 工作流使用场景。
在正式撰写前,请先向我追问 5 个必要问题,用于补充项目细节。问题应围绕以下信息展开:
1. 项目名称、目标用户、核心场景
2. 当前使用的模型/平台/工具链
3. 是否有多 Agent 协作、长链推理、工具调用、自动化执行、人工审核闭环
4. 已落地成果、用户规模、调用量、Token 消耗、效率提升等量化信息
5. 可提供的证明材料类型,如账单截图、日志、GitHub、Demo、文章、用户反馈等
等我回答完后,请按以下结构输出,内容必须真实、具体、专业,不要空泛,不要只写口号,也不要虚构数据。
## 一、目前主要使用的底层模型系列
请根据我提供的信息,整理我主要使用过的模型系列,并按以下范围归类:
Claude、Gemini、GPT、MiMo、DeepSeek、豆包、MiniMax、GLM、Qwen 和其他模型。
每一类都要简单说明我主要把它用在什么场景里,例如:代码生成、资料分析、长文本写作、多模态理解、Agent 工作流、语音生成、内容审核、自动化脚本生成等。
不要只罗列名称,要写出“模型 + 用途”的对应关系。
## 二、AI 驱动构建的具体成果
请写一段 100 词以上、800 字以内 的项目介绍,语气真实、具体、专业,不夸张。必须包含以下要素:
1. 项目解决的核心痛点
2. 项目的目标用户或使用场景
3. 项目的核心逻辑流,尤其要突出是否包含:
- 长链推理
- 多 Agent 协作
- 工具调用
- 自动化执行
- 人工审核闭环
- 动态生成脚本或任务分解
4. 当前已经取得的实际成果,比如:
- 已落地使用
- 提升效率
- 生成内容数量
- 代码提交数量
- 用户反馈
- Demo
- 作品链接
5. 我计划如何使用 MiMo V2.5 或 MiMo API 的 Token 权益 继续推进项目,重点说明为什么需要更多 Token,以及这些 Token
会用于哪类高频、长上下文、复杂推理或多轮 Agent 任务
如果项目中有大量 AI 编码、Agent 对话、文字生成、数据分析、自动化运维、批量实验等高频调用,也请明确写出来,尽量量
化 Token 消耗潜力,比如日均请求量、平均轮次、上下文长度、任务复杂度、并发场景等。
## 三、使用证明与影响力证明
请根据我提供的材料,整理一份可上传的证明清单,并按优先级排序。
优先级判断标准是:越能证明“我真的在高频使用 AI 并且已经产生真实成果”的材料,优先级越高。
可包含以下类型:
1. 过去 30 天主流 AI 平台账单截图
2. Agent 工作流运行截图、终端日志、录屏
3. GitHub 项目链接
4. 产品 Demo 地址
5. 公众号文章、知乎文章、博客链接
6. 用户反馈、社群讨论、实际使用截图
7. 项目文档或功能截图
请你输出时明确告诉我:
- 哪些材料最能提高通过率
- 哪些材料适合作为主证据
- 哪些材料适合作为补充证据
- 如果材料不足,建议我补充什么
## 四、最终输出格式
请最终输出两版内容:
### 第一版:正式申请版
适合直接复制到申请表里,表达清晰、具体、可信。
### 第二版:精简版
控制在 300 字以内,适合表单空间有限时使用。
## 写作要求
- 只能基于我提供的真实信息整理,不要编造
- 重点突出“长链推理”“智能体协同”“真实 Token 消耗”“已落地成果”
- 避免“探索 AI 未来”“提升生产力”“赋能创作者”这类空泛表达
- 尽量写得像真实项目申请材料,不要像宣传稿
- 如果信息不够,请先问完 5 个问题再写,不要直接生成正文参考经验帖
https://zhuanlan.zhihu.com/p/2033503799235589648
https://linux.do/t/topic/2088722
https://linux.do/t/topic/2086245
https://linux.do/t/topic/2086115
https://linux.do/t/topic/2091044